

Blending is hard, machines do it better
In the first two parts of this article we looked at why machines are better than humans (at some things), and how swarms of machines will be the next disruptive force in the Industrial Internet of Things (IIoT). Now it’s time to explore a real use case to back up these arguments. We’ll start with a simple example for newbies, and then add complexity – stick with us if you’re an expert…
An easy (!) math problem
Mixing raw materials together as input to a production process, or to make a new or intermediate product, should be an easy task. It’s certainly a common one, from the food industry through to the production of metals, paints, and even the use of crude oil at a refinery. The goal is normally to make a product that matches specific quality or regulatory criteria (taste, percentage of a certain element, tannin levels in wine, and so on) at the lowest possible cost. The classic approach to solving this problem is to use linear programming to find the optimal solution. Here’s a brief example, borrowed from Paul Jensen at Texas University.
Animal Feed Blending Problem: the goal is to find the lowest cost to produce a kilogram of animal feed, blended from three ingredients with the following characteristics:

There are a set of constraints: the blend must have a minimum of 0.8% and a maximum of 1.2% calcium, it must have at least 22% protein, and at most 5% Fiber. You can plot this as a graph, or use a specific linear programming tool – we simply plugged the numbers into Excel, which has a built in ‘Solver’ add-in to determine this type of linear problem. After a few seconds, Solver informs us that the best mix for the lowest cost is 28g Limestone, 648g Corn, and 324g Soybean for a total cost of $0.4920 per kg.
For fun, we can switch the model and ask for the maximum price that meets the constraints (why? maybe we’re selling limestone, corn and soybean, and recommending the ‘perfect’ recipe to our partners!), the answer in this case is $0.6024, giving us a spread of $0.11038. It may not seem huge, but if we are producing a million metric tons a year, that’s a saving of more than $110,000.
The oil refinery. Suddenly, not such an easy problem
Great, you say, problem solved. Unfortunately, while the ingredients-mixing challenge can be solved easily enough, this is only possible because there are linear relationships between the components. The real world doesn’t always operate so smoothly. Let’s look at an oil refinery. In this theoretical example, we have 2000 containers, and each holds a certain volume of crude oil, purchased at a fluctuating market price. The oil has various percentages of contaminants such as sulfur, iron, and heavy metals like vanadium, as well as varying amounts of different hydrocarbons. We have unique processes to refine and separate the constituent parts, and each approach has a different cost. We are about to make a product (say jet fuel), and can blend up to 5 containers before we start the refinery process. Our goal in this case, is to find the cheapest blend (factoring in both the initial purchase price, plus the level of each contaminant and the cost to extract). As in the prior example, we have a set of constraints that shows how much contaminant is permitted in the finished product, the number of bbl required (barrels of oil), and finally the percentage of ‘raw’ materials (hydrocarbons of our target chain length) that must be in the mixture.
We can’t solve this using linear programming, since there is no straight line – the values of the contaminants per container and the pricing, appears somewhat random. The most obvious solution is simply to calculate the combinations, and sort them into price sequence, so we can take the lowest cost option. The number of combinations is:
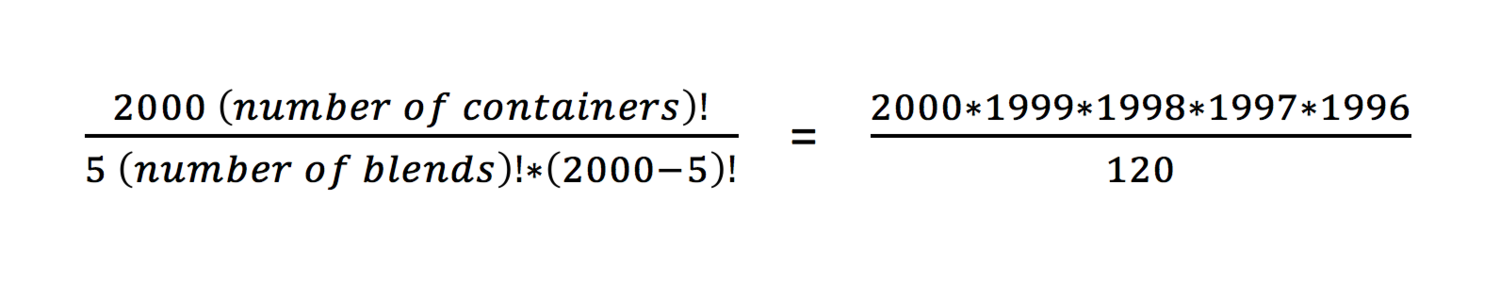
= 265,335,665 000,400 combos
= 265 trillion combinations, in simple language
Add in a few other real-world factors, and remember that we must do several calculations for each combination and then sort the list, and suddenly you have what the data scientists call an NP-complete problem, by which they mean you can’t throw raw power at this and expect to get an answer in your lifetime. There is a solution though… genetic (or evolutionary) algorithms.
Excel can do this too :)
The Solver add-in to Excel has the capability to run an evolutionary algorithm for this type of non-linear problem. Without going too deep here, the idea is to pick a random sample of containers to blend, and then compare this to a population of other random samples, and to use some standard genetic approaches to improve the solution (such as crossover, mutation, and selection, all of which look to evolve the solution and find an improved result). We ran a simulation of the oil refinery blending problem, with 2000 containers split across three physical locations, with 3 blends, and a handful of constraints. The screen shot shows an example:
The algorithm typically took 2-5 minutes to run, and as in the case above, it didn’t always find a solution (each red dot shows a constraint out of bounds). Running it multiple times often gave a positive result in the end. However, one downside to evolutionary approaches is that you typically get different results each time, and while you may approach an optimum solution, there’s no guarantee that you’ve found the best (i.e. optimal) solution. You can help Solver by letting it run for longer, but that’s not always practical, especially if there are decisions to be made quickly.

Let the machines do it for you
Next, we tried a different approach to this problem, based on collaborating machines. We ran a simulation where each container was an independent agent. When the refinery requests a blend (with constraints as before), each container/agent looks at its values and calculates how near it is to the perfect match. [Yes, this as a dating algorithm!] In each location, the container/agent that is the closest match then looks for a ‘mate’, by broadcasting a message locally, seeking a container to blend with to make it an even better fit for the original requirements. We repeat this process with that mate too, resulting in a three-way blend (and could go n-layers deep at minimal extra cost). Here are the results, based on the same criteria as before:

The results in the bottom right corner show that we found a blend that met the criteria in two of the physical locations – remember that the evolutionary approach did not find a solution. Over repeated simulations, we have seen collaborating agents consistently find a blend that:
Delivers 2-3% lower costs than an evolutionary algorithm
Matches all criteria in a much higher percentage of scenarios (but not all – there are situations where a solution doesn’t exist)
Delivers results in real-time
That last point is probably the most important, because nobody is interested in simply building a better mousetrap. So let’s look at that last point again: the agents deliver their results immediately – we change a parameter, and the recommended blend is displayed. By contrast, each run of the genetic algorithm takes 2-3 minutes (and sometimes upwards of 10 minutes), plus we sometimes need to run it multiple times to find any acceptable solution.
There are two good reasons why the agents can perform in real-time. Number one, they have a more efficient algorithm, that doesn’t require hunting through a subset of the trillions of potential combinations. Number two, each container/agent has a small but dedicated CPU*, which means the agents are effectively an MPP (massively parallel processing) system.
What’s so special about real-time?
We're running a simulation here, but one that is a very real situation for many organizations, and there are significant complexities beyond the scenario we’ve described. In oil & gas, for example, there are intermediate products and postponement strategies, along with additives that need to be introduced to the blend. That’s only the tip of the iceberg:
“The problem is further complicated by including some important logistics details [such as]… sequence dependent switchovers, multipurpose product tanks and blender units, minimum run-length requirements, fill-draw-delay, constant blend rate, one-flow out of blender, maximum heel quantity, and downgrading of product to lower quality. The variables associated with logistics details are combinatorial variables and have an exactly one-to-one correspondence with quantity sizing variables. This combinatorial characteristic of the logistics problem makes the optimization problem NP hard.”
Nikisha K. Shah, Zukui Li, and Marianthi G. Ierapetritou, Dept of Chemical & Biochemical Engineering, Rutgers University
The result is that people have tended to tackle each subset of the broader supply chain problem independently, and then looked for ways to integrate and/or co-ordinate these disparate solutions into an enterprise-wide system. This means that for most organizations, blending and logistics, production, et al, are activities that are planned in advance. When there are disruptions, delays, and changes to the business environment (like the price of a barrel of oil) - all of which occur daily - then an army of planners revise the schedule. In the meantime, processes function in a sub-optimal fashion, even after replanning, because organizations are deploying algorithms that can’t respond with great solutions in the given time window, since these are ‘NP hard’ problems.
The Future
You could argue that the solution above could be run as effectively with a python script across an MPP (Massively Parallel Processing) system, and doesn’t require agents. In this first step, that may be true. There is another aspect, though. If you combine the agent algorithm with the latest AI approaches on Deep and Reinforcement Learning, so that each device can begin to learn how to improve the process, then you have a hugely powerful new way to tackle single and multiple objective problems. Such as blending. A swarm intelligence / agent-based system that can operate in real time, cope with disruptions, and learn by itself how to continually improve the process, would be, well, disruptive. That is something we have added to the model, and you can look out for a future blog to see how that changes results over time, in surprising ways.
We believe strongly that the future will be won by organizations that enable their machines to collaborate in solving problems, guided by human mentors.
By the way, if you have a challenge with blending, or want to discuss how your machines might collaborate to solve a problem, I’d love to talk with you!
Drop me a line: anthony@swarm.engineering
*We can allocate one or multiple agents per CPU, and run this in the cloud or on edge devices. Today, many of the use cases live in the cloud because that’s where the data resides. In the future, the reverse may become the de-facto standard.